
What is the use of Kafka?
Kafka stores data as a stream of continuous records which can be processed in different methods. Kafka can be used as a FIFO queue, as a Pub/ Sub messaging system, a real-time streaming platform, and as a Database. Let’s start by answering the question “What is Kafka?”. Let’s try to understand those jargons.
What is the scope of Kafka in software testing?
Testing professionals have a good scope in Kafka in terms of Queuing and Messaging systems. Architects – since everything needs some framework and this framework can be updated from time to time. Big Data architects would find Kafka a good career investment.
What is a Kafka cluster and how does it work?
A Kafka cluster is a group of broker nodes working together to provide, scalability, availability, and fault tolerance. One of the brokers in a cluster works as the Controller, which basically assigns partitions to brokers, monitors for broker failure to do certain administrative stuff.
What is Kafka producer and subscriber?
With Kafka, one can collect these data streams for processing by frameworks such as Spark Streaming. In a publish-subscribe messaging system, systems called publishers send streams of messages. These are the producers, since they produce messages. Another set of systems, called subscribers, read those messages.

Are Kafka messages consumed in order?
To completely answer your question, Kafka only provides a total order over messages within a partition, not between different partitions in a topic. ie, if consumption is very slow in partition 2 and very fast in partition 4, then message with user_id 4 will be consumed before message with user_id 2.
Is Kafka exactly once delivery?
Initially, Kafka only supported at-most-once and at-least-once message delivery. However, the introduction of Transactions between Kafka brokers and client applications ensures exactly-once delivery in Kafka.
Is Kafka push or pull?
Since Kafka is pull-based, it implements aggressive batching of data. Kafka like many pull based systems implements a long poll (SQS, Kafka both do). A long poll keeps a connection open after a request for a period and waits for a response.
Is Kafka exactly once or at least once?
At most once — This is “best effort” delivery semantics. Consumers will receive and process messages exactly once or not at all. At least once — Consumers will receive and process every message, but they may process the same message more than once.
Is Kafka transactional?
Transactions in Kafka are designed so that they are mainly handled on the producer/message broker side, rather than the consumer side. The consumer is effectively an idempotent reader, while the producer/coordinator handle the transaction.
How does Kafka ensure exactly once delivery?
A batch of data is consumed by a Kafka consumer from one cluster (called “source”) then immediately produced to another cluster (called “target”) by Kafka producer. To ensure “Exactly-once” delivery, the producer creates a new transaction through a “coordinator” each time it receives a batch of data from the consumer.
Is Kafka a message bus?
What is Apache Kafka? Kafka is a message bus developed for high-ingress data replay and streams. Kafka is a durable message broker that enables applications to process, persist, and re-process streamed data.
Does Kafka use long polling?
Since Kafka is an event streaming platform, the common option for dealing with such a problem is long polling.
Is Kafka poll based?
The poll() method is the function a Kafka consumer calls to retrieve records from a given topic. When calling the poll() method, consumers provide a timeout argument. This is the maximum amount of time to wait for records to process before returning. At the end of the day, this method is really a fancy do...
Can Kafka have duplicates?
It's the easiest way to have a deal with duplicate messages. The message handler is idempotent if calling it multiple times with the same payload has no additional effect. For example, modify an already modified Order with the same payload should give the same result.
How do I order messages in Kafka?
Short AnswerInitialize the project.Get Confluent Platform.Create the Kafka topic.Describe the topic.Configure the project application.Set the application properties.Create the Kafka Producer application.Create data to produce to Kafka.More items...
Is RabbitMQ exactly once?
In RabbitMQ, exactly-once delivery is not supported due to the combination of complex routing and the push-based delivery. Generally, it's recommended to use at-least-once delivery with idempotent consumers.
What is a Kafka cluster?
Cluster. A Kafka cluster is a group of broker nodes working together to provide, scalability, availability, and fault tolerance. One of the brokers in a cluster works as the Controller, which basically assigns partitions to brokers, monitors for broker failure to do certain administrative stuff. 0 reactions.
How does Kafka work?
Kafka works as a cluster of one or more nodes that can live in different Datacenters, we can distribute data/ load across different nodes in the Kafka Cluster, and it is inherently scalable, available, and fault-tolerant. 0 reactions.
What is partition in Kafka?
Partition is analogous to shard in the database and is the core concept behind Kafka’s scaling capabilities. Let’s say that our system becomes really popular and hence there are millions of log messages per second. So now the node on which appLogs topic is present, is unable to hold all the data that is coming in. We initially solve this by adding more storage to our node i.e. vertical scaling. But as we all know vertical scaling has its limit, once that threshold is reached we need to horizontally scale, which means we need to add more nodes and split the data between the nodes. When we split data of a topic into multiple streams, we call all of those smaller streams the “Partition” of that topic.
What is a producer in Kafka?
A producer is the Kafka client that publishes messages to a Kafka topic. Also one of the core responsibilities of the Producer is to decide which partition to send the messages to. Depending on various configuration and parameters, the producer decides the destination partition, let’s look a bit more into this.
What is a message in Kafka?
A message is the atomic unit of data for Ka fka. Let’s say that you are building a log monitoring system, and you push each log record into Kafka, your log message is a JSON that has this structure.
Is Kafka a good software?
Kafka is a great piece of software and has tons of capabilities and can be used in various sets of use cases. Kafka fits great into Modern-day Distributed Systems due to it being distributed by design. It was originally founded at LinkedIn and currently maintained by Confluent. It is used by top tech companies like Uber, Netflix, Activision, Spotify, Slack, Pinterest, Coursera. We looked into the core concepts of Kafka to get you started. There are tons of other things like Kafka Stream API or kSql that we did not talk about in the interest of time.
Can Kafka be used as a database?
And because of the durable storage capability of Kafka, it can even be used as a Database ( read about it here ). 0 reactions.
What is Kafka used for?
Having said all of that, Kafka is commonly used for real-time streaming data pipelines, i.e. to transfer data between systems, building systems that transform continuously flowing data, and building event-driven systems. We will jump into core Kafka concepts now.
What is Kafka streaming?
Kafka is a Distributed Streaming Platform or a Distributed Commit Log. Let’s try to understand those jargons. Distributed. Kafka works as a cluster of one or more nodes that can live in different Datacenters, we can distribute data/ load across different nodes in the Kafka Cluster, and it is inherently scalable, available, and fault-tolerant.
What is partition in Kafka?
Partition is analogous to shard in the database and is the core concept behind Kafka’s scaling capabilities. Let’s say that our system becomes really popular and hence there are millions of log messages per second. So now the node on which appLogs topic is present, is unable to hold all the data that is coming in. We initially solve this by adding more storage to our node i.e. vertical scaling. But as we all know vertical scaling has its limit, once that threshold is reached we need to horizontally scale, which means we need to add more nodes and split the data between the nodes. When we split data of a topic into multiple streams, we call all of those smaller streams the “Partition” of that topic.
What is a producer in Kafka?
A producer is the Kafka client that publishes messages to a Kafka topic. Also one of the core responsibilities of the Producer is to decide which partition to send the messages to. Depending on various configuration and parameters, the producer decides the destination partition, let’s look a bit more into this.
What is a message in Kafka?
A message is the atomic unit of data for Kafka. Let’s say that you are building a log monitoring system, and you push each log record into Kafka, your log message is a JSON that has this structure. When you push this JSON into Kafka you are actually pushing 1 message.
What does it mean when you push data to Kafka?
When you push data to Kafka it takes and appends them to a stream of records, like appending logs in a log file or if you’re from a Database background like the WAL. This stream of data can be “Replayed” or read from any point in time.
Is Kafka a good software?
Kafka is a great piece of software and has tons of capabilities and can be used in various sets of use cases. Kafka fits great into Modern-day Distributed Systems due to it being distributed by design. It was originally founded at LinkedIn and is currently maintained by Confluent. It is used by top tech companies like Uber, Netflix, Activision, Spotify, Slack, Pinterest, Coursera. We looked into the core concepts of Kafka to get you started. There are tons of other things like Kafka Stream API or kSql that we did not talk about in the interest of time.
Kafka
Goal: Create a distributed messaging system to handle large-scale streams of messages.
Introduction
How can a cluster of computers handle the influx of never-ending streams of data, coming from multiple sources? This data may come from industrial sensors, IoT devices scattered around the world, or log files from tens of thousands of systems in a data center.
Kafka
Kafka is an open-source high-performance, distributed, durable, fault-tolerant, publish-subscribe messaging system. We will cover every one of these points as we explore this system.
Publish-Subscribe Messaging
In a publish-subscribe messaging system, systems called publishers send streams of messages. These are the producers, since they produce messages. Another set of systems, called subscribers, read those messages. These are the consumers, since they consume the messages.
What is Kafka software?
What is Kafka? The open-source software platform developed by LinkedIn to handle real-time data is called Kafka. It publishes and subscribes to a stream of records and also is used for fault-tolerant storage. The applications are designed to process the records of timing and usage.
What is the advantage of Kafka?
High Throughput: It can easily handle a large volume of data when generating at high velocity is an exceptional advantage in Kafka’s favour. This application lacks huge hardware to support message throughput at a frequency of thousands of messages per second.
How many commas does Kafka use?
LinkedIn, Microsoft and Netflix process four-comma messages a day with Kafka ( nearly equals to 1,000,000,000,000). It is used for real-time data streams, collecting big data, or doing real-time analysis (or both). Kafka is used with in-memory microservices to provide durability, and it can be used to feed events to CEP ...
How does Kafka work?
This increased performance in behaviour is dedicated to its stability, its provision to reliable durability, with its flexible inbuilt capability to publish or subscribe or queue maintenance.
What is Kafka's key behaviour?
Kafka’s crucial behaviour that set it apart from its competitors is its compatibility with systems with data streams – its process enables these systems to be aggregate, transform, and load other stores for convenience working. “All the above-mentioned facts would not be possible if Kafka was slow”.
Is Kafka a real time data analytics?
At present, Kafka has become the de-facto standard for real-time data analytics with the highest precision in microseconds. We have presented our insights in terms of data and details in support of Kafka technologies. Several big companies are harnessing data daily; in doing this, they need professionals to harness these huge data sets. With Kafka, one can be assured to lead their career in BigData analytics.
Does FIFO limit throughput?
However, FIFO still effectively limits throughput on a group to a single publisher and single subscriber. If there are multiple publishers, they have to coordinate to ensure ordering is preserved with respect to our application’s semantics.
Do FIFO queues guarantee delivery?
The more interesting caveat is that FIFO queues do not guarantee exactly-once delivery to consumers (which, as we know, is impossible ). Rather, they offer exactly-once processing by guaranteeing that once a message has successfully been acknowledged as processed, it won’t be delivered again.
Understanding Kafka
Kafka is an Open-Source software program that lets you store, read, and analyze streaming data. It is free for everyone to use and is supported by a large community of users and developers who consistently contribute to new features, updates, and support.
Key Features of Kafka
With Apache Kafka, users can scale in all four dimensions: Event Producer, Event Processor, Event Consumer, and Event Connector. You can scale effectively with Kafka without experiencing downtime.
Top 6 Kafka Alternatives
Kafka is a widely used publish-subscribe-messaging service known for managing large volumes of information, handling both online and offline messages. However, Kafka has some shortcomings such as slow speeds, message tweaking, lesser message paradigms, and more, thereby increasing the usage of Kafka Alternatives.
Conclusion
In this article, you learned about Kafka, its features, and some top Kafka Alternatives. Even though Kafka is widely used, the technology segment has advanced to the point where other options can overshadow Kafka’s cons. There are various options available for choosing a stream processing solution.
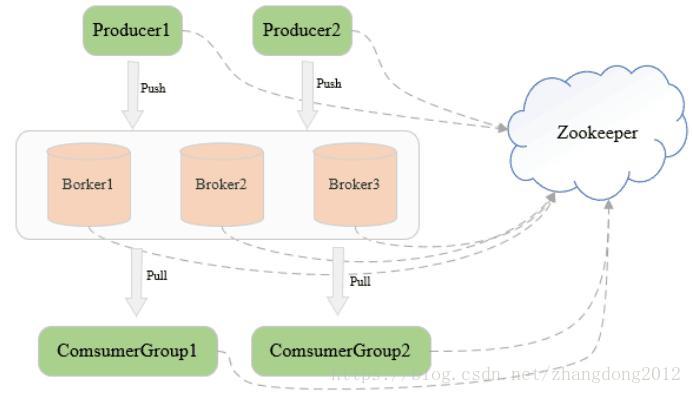
Understanding Kafka
How Does Kafka Work So easily?
What Can You Do with Kafka?
- If your company plays with huge sets of data regularly, you need Kafka. There is a long list of companies using it. 1. LinkedIn uses it to track data and operational metrics. 2. Twitter to provide stream processing infrastructures. There is a long list of companies from Uber to Spotify and Goldman Sachs to Cisco.
Advantages
- Given below are the advantages mentioned: 1. High Throughput:It can easily handle a large volume of data when generating at high velocity is an exceptional advantage in Kafka’s favour. This application lacks huge hardware to support message throughput at a frequency of thousands of messages per second. 2. Low Latency:Low latency handling this high volume mes…
Required Skills
- There is no special requirement for being a Kafka professional. But we have underlined some streams and professionals: 1. Developers who willingly want to make a career in Big Datastream and want to accelerate their career. 2. Testing professionals have a good scope in Kafka in terms of Queuing and Messaging systems. 3. Architects – since everythin...
Why Use Kafka?
- For the purpose of data tracking and manipulating them as per the business need, it is preferred worldwide. It gives the possibility to stream data in real-time with real-time analytics. It is fast, scalable, and durable, and designed as fault tolerance. There are multiple use cases present over the web where you can see why JMS, RabbitMQ, and AMQP are not even considered to work wit…
Scope
- It is doing great all across the globe. Well, we are not saying this rather stats. Salary Stats for Kafka Professionals – PayScale 1. Software Engineer – $109,825 2. Data Engineer – $109,580 3. Developers – $81,182 4. Senior Data Engineer – $ 127, 836
Conclusion
- At present, Kafka has become the de-facto standard for real-time data analytics with the highest precision in microseconds. We have presented our insights in terms of data and details in support of Kafka technologies. Several big companies are harnessing data daily; in doing this, they need professionals to harness these huge data sets. With Kafka, one can be assured to lead their care…
Recommended Articles
- This has been a guide to What is Kafka? Here we discussed the working, scope, career growth, and advantages of Kafka. You can also go through our other suggested articles to learn more – 1. Kafka Event 2. Kafka Listener 3. Kafka Zookeeper 4. Kafka Partition Key